Git is a distributed version-control system for tracking changes in source code during software development. It is designed for coordinating work among programmers, but it can be used to track changes in any set of files. Its goals include speed, data integrity, and support for distributed, non-linear workflows.

If you are familiar with SVN(Subversion) or CVS(Concurrent Version System), you may have no difficulty in using Git.
The characteristics are as followings:
- Strong support for non-linear development
- Distributed development
- Compatibility with existent systems and protocols such as HTTP, FTP, SSH and etc.
- Efficient handling of large projects
- Cryptographic authentication of history
- Toolkit-based design
- Plug-gable merge strategies
- Garbage accumulates until collected
- Periodic explicit object packing
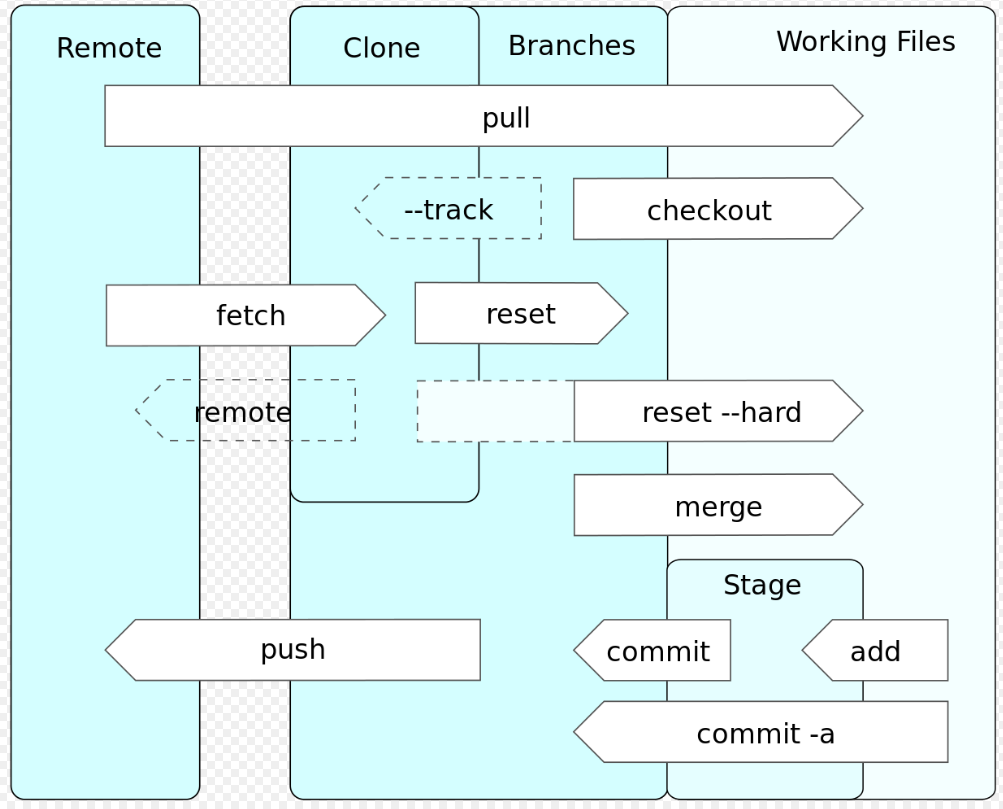
Data flows
- Git has a data revision control system in storage level with its version information. And you will be faced an unfamiliar words like clone and branch.
- A clone is a copy of all the code on the master branch - it is an exact replica of the code on git server.
- A branch is a slightly changed or modified section of code that meets different objectives.
- git clone command copies an existing Git repository - it is primarily used to point to an existing repo and make a clone or copy of that repo at in a new directory, at another location. The original repository can be located on the local file system or on remote machine accessible supported protocols.
Other information